Introduction
If a DBA knows one thing about Columnstore Indexes is that it is stored in columns rather than rows and that is where the performance benefit comes from when we are talking about aggregations, however much further than that they can be a bit of a mystery. When to use them and how to use them isnt second nature to the average OLTP production DBA. However they can be very useful to all types of envrionments if used correctly. This article will go through the relevant internals of the column based storage of a Columnstore index.
Storage internals
When talking about Column Based storage
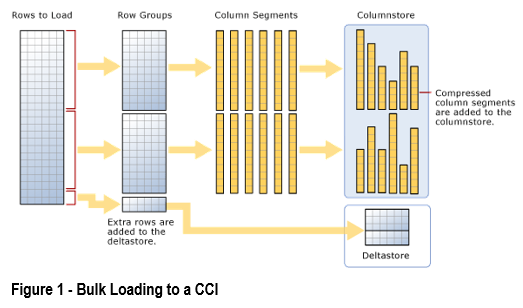
- Each column is stored in a structure called a Row Group
- Each row Group stores roughly 1 million rows.
- When SQL creates a Columnstore Index it will attempt to populate a row group fully, this means we will always have a partially full row group at the end with the remainder of rows which aren’t 1 million rows full.
- This remainder can take two forms
- If the number of rows remaining are above roughly 100,000 then it is stored in another RowGroup.
- If the number is less than 100,000 then it is stored in something called the Delta Store as a Delta Group this delta group will be a B-Tree as you see in normal indexes, it does not contain enough rows to performantly transform into a row group and store in the columnstore.
After row groups are built SQL Server then will combine all its column data on a per row group basis and compresses these groups. The rows within a Row Group can be re-arranged if this helps to get a better compression. Column data within a row group is called a Segment. SQL will load an entire segment into memory when that data is needed, SQL also stores segment metadata with minimum and maximum values etc.
Quick Recap
- Columns are stored in Row Groups
- Each row group stores roughly 1 million rows
- Row groups are populated fully with 1 group at the end with remainder of rows
- If that group is > 100,000 it is stored as a row group
- If that group is < 100,000 it is a stored as a delta group
- Indexes are compressed on a per row group basis
- Column data within a row group is called a Segment
- Segment metadata stores minimum and maximum values
Compression
During compression SQL Server replaces all values with 64 bit integers using 2 possible algorithms:
Dictionary Encoding
This encoding stores distinct values from the data in a separate structure called a dictionary. Every value has unique id assigned. SQL Server replaces the actual data with a unique id from the dictionary, SQL then holds a global dictionary which is shared across all segments that belong to the same index partition to be able to keep track of all IDs. A crude example can be seen below:
Value Based Encoding
This is mainly used for numeric and integer datatypes that do not have duplicated values. In this scenario dictionary compression is in-efficient. This type of encoding aims to compress these values to a smaller range of 64 bit integers. To learn more about encoding and compression in ColumnStore indexes this is a great article
After encoding takes place SQL Server then goes ahead and compresses the data and stores it as a LOB allocation unit. If you were to drill into the dmvs you will find that the index also holds an IN_ROW_DATA allocation, however no data is stored here, it is needed to have a LOB allocation.