Introduction
Understanding how BigQuery processes its queries goes along way in learning how to performance tune them. Much like SQL Server Big Query goes through a series of steps upon query execution to be able to produce the data back to you. In SQL this is refered to as the Query Optimizer in BigQuery this is known as Dremel which is the name of the query engine.
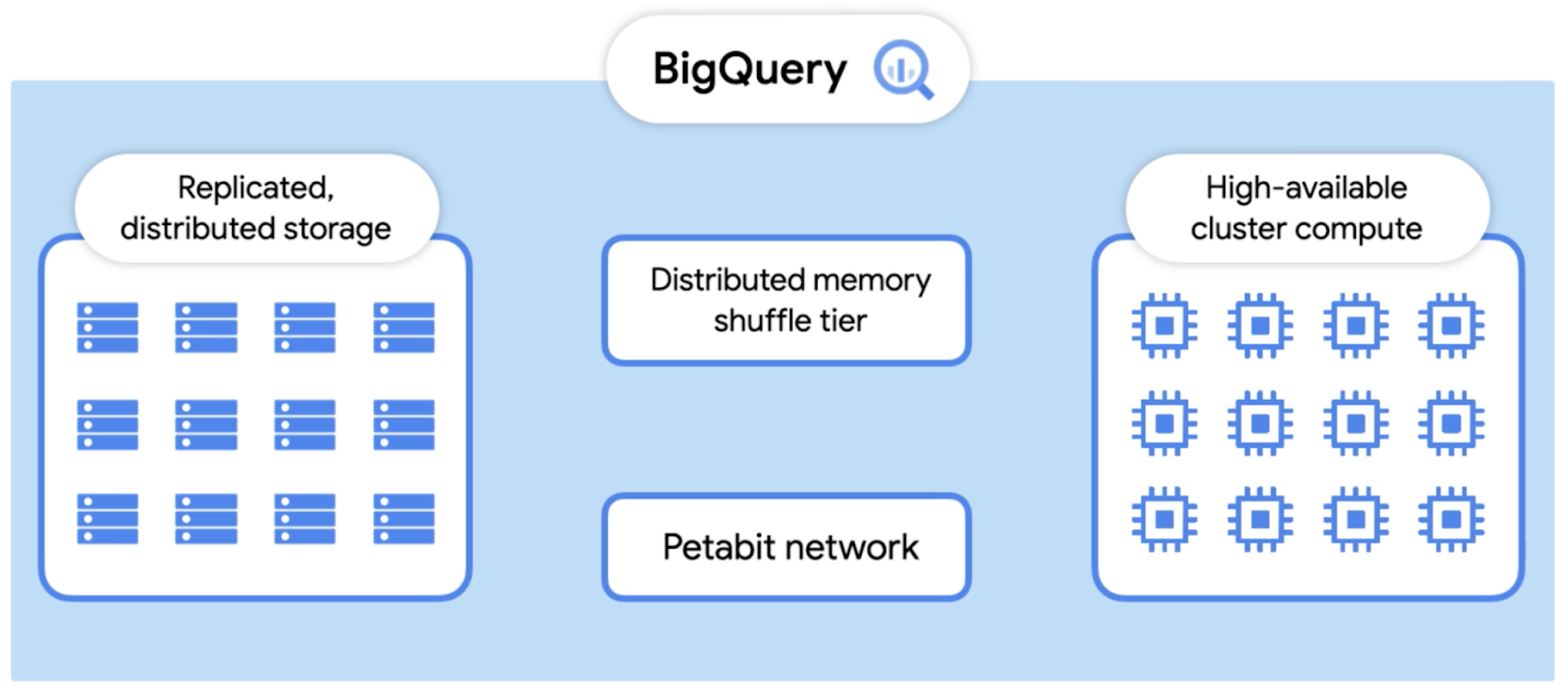
Above is a visual representation of Dremel. Dremel much like other scale out technologies utlizes multiple compute nodes (worker nodes) to carry out different actions. With BigQuery it uses something called a Distributed Memory Shuffle Tier.
When a query is actioned:
- The Worker will get data from the storage layer
- The Worker will store intermediate data in the Shuffle Tier
- Once the data is in the shuffle tier it can then be accessed by all other workers
With all these workers grabbing and actioning data this gives it the great performance. As well as that the shuffle tier enables BigQuery to cache its data as well making it speedier for the same/similar queries on the next run. Once all workers have completed their work, data is then persisted to storage and returned to the user.
Query Processing
With a good understanding of the high level of how Dremel works lets move onto the Query Processing layer. You may notice that Query Processing is somewhat similar to SQL Server. An explanation of the SQL Server Internals can be found below.
Below is a visual representation of how Query Processing works in BigQuery
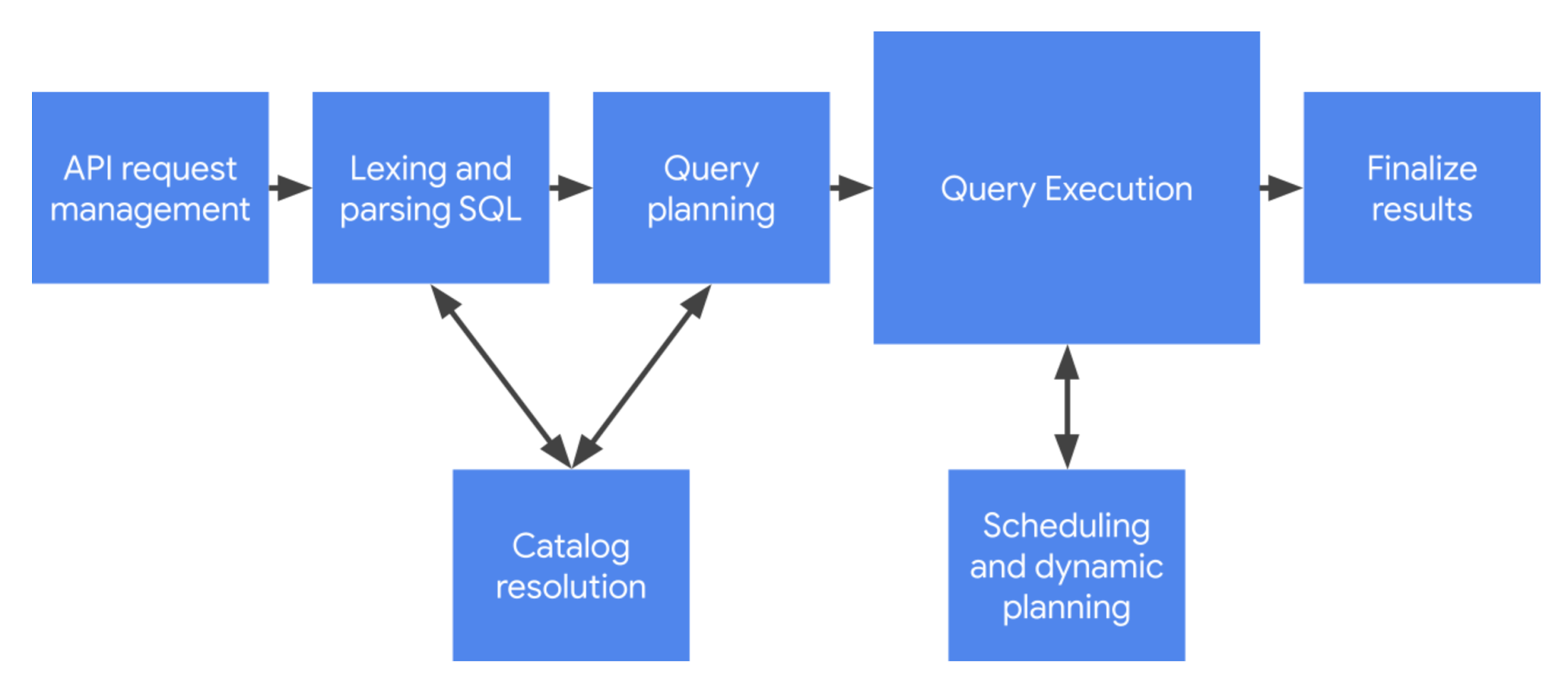
API Request Management
Each query will trigger this API when a query is run, it will then be polled until a success code is returned along with the data. This layer will handle:
- Authenticating and Authorizing
- Tracking metadata about the query
Lexing and Parsing SQL
Now this process is very similar to the Query Parsing process in SQL Server
- SQL Server
- Query Parsing - Will ensure that the SQL is formed correctly. It will create a Parse Tree for use after the parsing Step
- BigQuery
- Lexing - Lexing is the process of converting the raw SQL statement into a series of tokens (similar to a Parse Tree)
- Parsing - The process of converting those series of tokens into a representation of the query to be used further on
Catalog Resolution
Again a very similar step to SQL Server. Once the query has gone through Lexing and Parsing and we know its syntactically correct and a plan can be created, it needs to now validate that the objects used in the query are valid and exist. This is what is known as Catalog Resolution in Bigquery, though you may know it as the Algebrizer in SQL Server.
Query Planning
Query Planning is the next step.
- We have parsed our query and we know it works Syntactically
- We have Resolved all catalogs and know all objects exist and are being used correctly.
The next step is planning how we are going to run this query. For BigQuery because it gains its performance by having worker nodes execute different aspects of the query, this step is crucial, as it will plan out what parts of the query can be handed off to what worker nodes.
Query Execution
Simply it takes the plan and executes it, it is represented as the execution graph you see in the GUI
![BigQueryExecutionGraph](/assets/images/BigQueryExecutionGraph.png{: .dark .w-75 .normal }
Query Management
The Workers do more than just execute the query. Workers are on standby to monitor as well as carry out adjustments during the process. Some workers will just be monitoring performance, and others will actually adjust the plan things like re-partitioning. This stage is important as it continually validates that the plan is correct, performance and going to get you the data in the quickest way.