Introduction
Partitioning in CosmosDB is probably the most important concept to learn if you want to create a scalable and performant system. Choosing the wrong partitioning structure will cost you timely and costly fixes down the road when you need to scale your design more.
Cosmos uses partitioning to horizontally scale. We know that :
- Within databases you can have multiple containers
- Within containers you can have multiple items.
For each container when you create it, you will specify a partition key. That partition key will be a property that you will insert into your items. Based on this key, cosmos will create logical partitions based on a certain value of your partition key.
When cosmos needs to scale, it will create more worker nodes (also known as physical partitions), it will then take whole logical partitions and place them on these new worker nodes. What you have now is different sets of your data across multiple nodes. This in theory allows for quicker access to your data, however the caveat is you must design your system in a way that you can seek to that data effectively. Let’s run through a scenario and a few examples. Keep in mind the below visual when thinking about scaling.
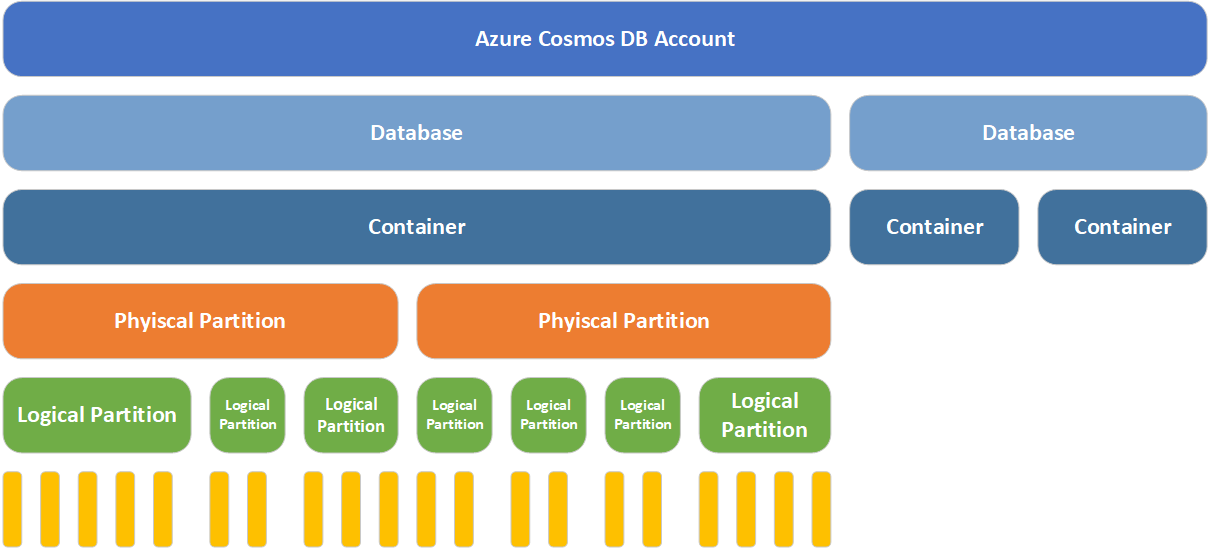
Scenario
You have an application that holds residential information for everyone in the UK. You have 1 container that holds all information to do with a persons address. An example item document is below.
1
2
3
4
5
6
7
8
9
{
"id": "1",
"FirstLineOfAddress": "8 Tite St",
"SecondLineOfAddress": "",
"County": "London ",
"PostCodePrefix": "SW3 ",
"PostCodeSuffix": "4JU",
}
Example 1
Partition Key: PostCodePrefix
If we select the PostCodePrefix for our partition key this will create logical partitions for each area in the UK.
- There are 124 postcode areas in the UK,
- Cosmos will have a limit of 124 logical partitions it can create
- Cosmos will have a limit of 124 worker nodes it can create
Example 2
Partition Key: County
If we select the County for our partition key this will create logical partitions for each County in the UK.
- There are 92 counties in the UK
- Cosmos will have a limit of 92 logical partitions it can create
- Cosmos will have a limit of 92 worker nodes it can create
Example 3
Partition Key: id
If we select the id for our partition key this will create logical partitions for each address in the UK.
- There are roughly 30 million addresses in the UK,
- Cosmos will have a limit of 30,000,000 logical partitions it can create
- Cosmos will have a limit of 30,000,000 worker nodes it can create
The above 3 examples is a very rudimentary example as to how logical partitions are chunked up and how cosmos can scale out. It shows that the more unique a partition key is then the more ability it has to scale out.
Example 3 sounds to be the best right? We have the ability to scale to 30 million worker nodes!
Yes and No. Example 3 is perfect for a write heavy workload. You would be able to write vast amounts of parallel data using this design, however what if you wanted to read it? Unless you were reading by predicating on the id itself, it would be quite hard for cosmos to know which partition the data was on, this can lead to more intensive reads and slower responses.
Example 1 and 2 would be examples of tailoring your application to read workloads. You have a lot less scope for scaling out however if you’re predicating by PostCodePrefix or County then Cosmos will find it easy to find which node your needed data is on.
There is another option however called a Synthetic Partition Key. A synthetic partition key allows you to join two properties together and partition on that. Now imagine if we did that on PostCodePrefix and PostCodeSuffix (Ignoring the fact that you could just have 1 field with postcode).
Final Example
Synthetic Partition Key: PostCodePrefix and PostCodeSuffix
If we select the PostCodePrefix and PostCodeSuffix for our synthetic partition key this will create logical partitions for each full postcode in the UK.
- There are 1.8 million postcodes in the UK,
- Cosmos will have a limit of 1,800,000 logical partitions it can create
- Cosmos will have a limit of 1,800,000 worker nodes it can create
Coined with the fact we can predicate our data by post code this is a really useful partition key to use. The takeaway from these examples is you should really be ensuring you know your data and your concepts before designing your partition key. I’ll leave you with some key questions to think about when designing your partition key.
- How will you read your data? – A partition key ideally should be a property you predicate on frequently
- How will you write your data? – A more unique partition key will give you better write performance and a better ability to scale out
- How many items do you expect to be under 1 value of a partition key ?- Cosmos has a 20GB limit for Logical partitions, ensure you won’t go above this