Introduction
Request units in Cosmos is a unit of measurement used to quantify the expense of database operations.
- All database operations have an RU cost
- Different types of operation have different cost
- Different types of operations on different size documents have a different cost
Below is an MS visual showing how RUs are used. They are a way to obfuscate Memory, CPU and IOPs into an easy to understand measurement allowing you to just concentrate on 1 cost rather than 3.
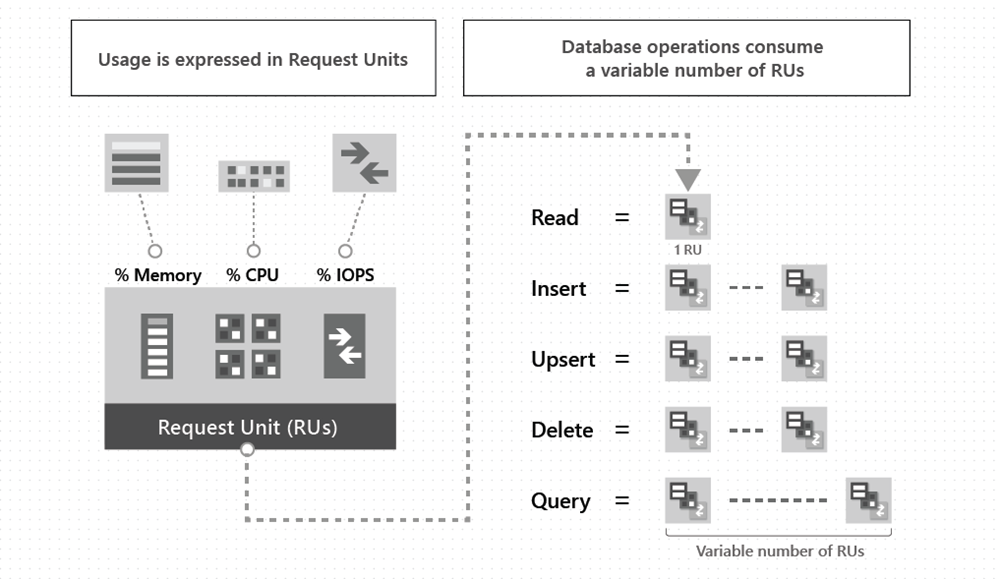
Request Unit Models
At present there are 3 Request Unit Models.
Provisioned Throughput Model
This model allows you to provision your own RUs. This is provisioned on a per second basis and can be incremented in 100 RUs at a time. When you provision a specific number of RUs, if you reach that limit, you will be throttled until you as a user intervene and increase the limit. This model is good for:
- Lower Environments
- Non Mission Critical systems
- Systems where cost is more important than performance
You can provision this RU Throughput at either the:
- Database Level
- Container Level
This allows you for more control on how you want to spread your RUs out.
Container Level
When you provision RU throughput at a container level, that container will always receive that throughput. This means you can always be 100% confident that the container will never have a throughput issue (unless you under provision).
Provisioning at a container level will mean a few things under the hood.
- The RUs will be provisioned evenly across all physical partitions in the container
- In Turn Throughput will be provisioned evenly across all logical partitions (assuming you have a good partitioning key that allows an - even spread of data)
- RUs cannot target Logical Partitions that is totally up to your partitioning model
- There is a possibility for a logical partition to rate limit others. By that i mean 1 Logical Partition could use up all the RUs and leave none for the rest. This can be resolved by increasing RUs
Another great MS visual is below which shows the architecture for physical and logical partitions.
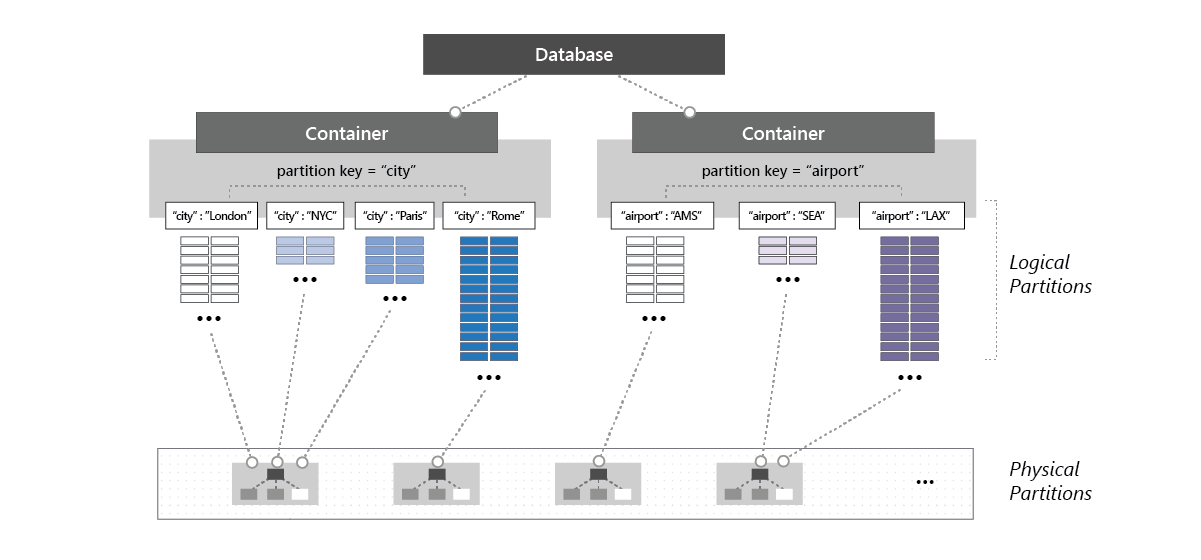
Database Level
Provisioning at a database level is another option for throughput, this means per database you set your RU limit, then all containers below will share the RU limit. This again could end up in rate limiting but this time at a container level.
Database level provisioning isn’t the suggested model, because it puts too many limits at a really high level, it doesn’t provide you with much control over your estate.
It’s not a predictable model, you wouldn’t be able to tell how much throughput each container would get, it would relate to a number of factors:
- Number of containers
- Partition key choice
- Logical partition distribution
AutoScale Model
Autoscale is another option that can be used with Provisioned. Instead of setting a hard limit and then having the system throttle itself, autoscale will allow you to set a limit but will automatically increase that limit if you meet it. This allows for not throttling and is perfect for mission critical systems.
This model is really useful for production workloads as it allows for the highest availability.
How does it work
With autoscale you still have to set a hard limit for RUs, but this can be a lot higher than if you were just using provisioned throughput. The equation for how autoscale is decided is below
\[0.1*Tmax <= T <= Tmax\]T=Throughput
Tmax=Maximum Throughput
Autoscale allows you to set your maximum throughput, it will then set your minimum throughput for you based on the above equation.
Example
You want to change from Provisioned Throughput to Autoscale. In provisioned throughput you have provisioned 50,000 RUs for a certain container. You are getting throttled occasionally though.
- Set up autoscale and set a maximum throughput of 70,000RUs
- Using the above equation Cosmos would set your minimum throughput as 7,000RUs
- Cosmos would then scale between 7,000 and 70,000RUs
This would resolve your situation as when you approached your 50,000 limit you would be allowed to exceed it
Cost
Cost is very simple here. You will be billed each hour for the highest throughput of the system within that hour.
Serverless Model
The serverless model unlike the provisioned model, does not require you to set a hard limit for RU throughput. Serverless will just continually scale to your applications needs, meaning you don’t need to worry about ever getting throttled.
You will only get billed for the RUs you use in your billing period. Serverless Model is really useful for applications where you don’t have continual traffic. For example:
- Staging Environments – Lesser Used will generally not be used barely at all overnight when no engineers are working.
- 9 – 5 Applications – Plenty of applications are engineered so they are only used in the working day. Meaning from 5pm-9am the next day there is no activity.
When there is no activity on your system, and you are using Provisioned Throughput then you are still being charged for the RU limit you set. With Serverless you will not be billed for inactivity.
Request Unit Capacity Planning
You need to keep in mind a number of factors when trying to capacity plan how many RUs you will most likely use. If you are converting from another database technology, then you should first trace its activity and find out all the access patterns and indexing. If it’s a new process, then you need to be starting your design from scratch.
Key factors to consider are set out by Microsoft on their MSDN page. These include:
- Item Size – As Items grow, so does RU cost. If you have an Item where fields are continually appended to then the RU cost will increase in line with the size.
- Item Indexing – The more indexes a container has the more RUs are used. If you don’t need an index on all fields, then remove unnecessary indexes.
- Item Property Count – If you have alot of indexes on one container then the more items you add the higher RU cost there will be to keep indexes up to date.
- Data Consistency – Strong and Bounded Staleness consistency levels use two times more RUs while perfoming read operations compared to other levels.
- Types of reads – Point reads cost alot fewer RUs than queries
- Query Patterns – Probably the most obvious one. Dependent on your queries cost will be more. If you’re bringing back more results, then RU cost will be higher. If you have multiple predicates, then cost will be higher etc. Try and tune your queries as much as possible.