Introduction
As a first point, noSQL is known as a Schema Free database technology. It allows for totally free unstructured data to be stored. CosmosDB is exactly the same, however the concept of Schema Design still resides and is useful to think of if you want to get the most out of the performance of CosmosDB
Relational Databases
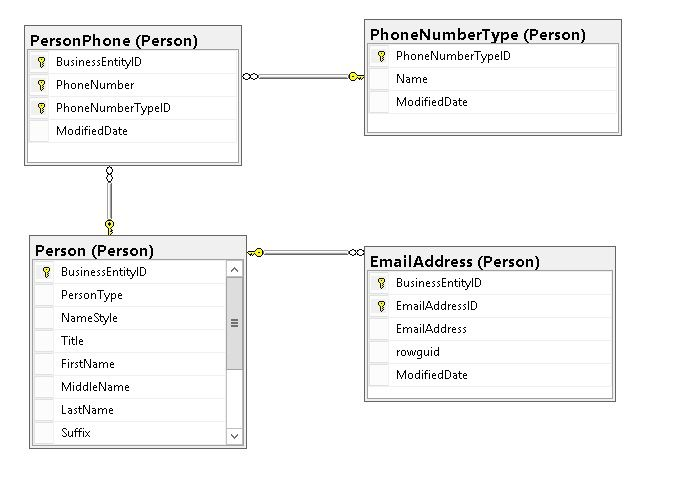
Commonly relational databases will have their schema designs in a normalized format, by that i mean having multiple tables with related data, whereby to get a full picture of that data you would join all the tables together to get any information you want. Something similar to the below can be thought of as a normalized design. You have a Person table as your main table, then child tables as such which hold important information about that person siloed into their own dataset. This enables use to keep our tables narrow and have very specific detailed tables.
De-Normalized data when thinking about relational databases would look something like the below, storing the first name and last name as columns and then storing multiple email addresses in a LOB column that can be ever increasing.

Below is a great blog which explains this in depth
noSQL Databases
Now noSQL databases will store their data as a document. Take Cosmos for an example, a normalized example of the above scenario would look like the below. 4 different documents. You would then get your information by making multiple calls to different documents
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
//PersonDocument
{
"BusinessEntityID": "",
"PersonType": "",
"NameStyle": "",
"Title": "",
"FirstName": "",
"MiddleName": "",
"LastName": "",
"Suffix": "",
"EmailAddressID": ""
}
//PersonPhoneDocument
{
"BusinessEntityID": "",
"PhoneNumber": "",
"PhoneNumberTypeID": "",
"ModifiedDate": ""
}
//PhoneNumberTypeDocument
{
"PhoneNumberTypeID": "",
"Name": "",
"ModifiedDate": ""
}
//EmailAddressDocument
{
"BusinessEntityID": "",
"EmailAddressID": "",
"EmailAddress": "",
"RowGUID": "",
"ModifiedDate": ""
}
Normalized data design isnt recommended for Cosmos it requires multiple reads as well as multiple writes to get your end result. Its fine to be used in really small use cases but it doesnt scale well in large environments.
Now the denormalized version of the above would look something like the below. See how you can all your information in one document, if you want to fine all personal details about 1 person its 1 read on 1 document. When you want to create or update details its 1 write to 1 document.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
{
"BusinessEntityID": "",
"FirstName": "",
"MiddleName": "",
"LastName": "",
"EmailAddresses": [
{
"EmailAddress":""
},
{
"EmailAddress":""
}
],
"PhoneNumbers": [
{
"PhoneNumber":""
},
{
"PhoneNumber":""
}
]
}
The above example works quite well. However you should be careful when creating documents where you embed child properties as an array. Doing this with things like PhoneNumber or EmailAddress is fine, there will never really be many possibilities of that for 1 person. If however this database is for Amazon, and this person record was to have an orders property. Under the persons document they would have a list of all orders they have ever purchases.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
{
"BusinessEntityID": "",
"FirstName": "",
"MiddleName": "",
"LastName": "",
"EmailAddresses": [
{
"EmailAddress":""
},
{
"EmailAddress":""
}
],
"PhoneNumbers": [
{
"PhoneNumber":""
},
{
"PhoneNumber":""
}
],
"Orders": [
{
"Order":""
},
{
"Order":""
}
{
"Order":""
}
{
"Order":""
}
{
"Order":""
}
{
"Order":""
}
{
"Order":""
}
]
}
This 1 person has a big amazon habit, the document would soon get so large that performance for reading would become slow and it could even exceed the document limit. This type of application should have a normalized format, a person document and an order document and then linked.
As with anything there is a trade off between read and write performance. When designing your schema you should be keeping in your mind:
- What are the percentage of reads and writes?
- Will data frequently be updated
- How easy will it be to update my data, will i need to update it in multiple places
- Will my design scale well, what if something becomes really popular will my design work.