Introduction

Google bigquery is googles Serverless data warehouse offering.
- It has a built in query engine that utilizes standard SQL to make it easier for administrators to query.
- It can query terabytes of data in seconds
- You do not have to manage/create indexes to ensure performance
Big Query creates an easy stepping stone from an OLTP solution like SQL Server into an OLAP type solution without the need to change much of your thinking. BigQuery stores its data and tables much like a relational database system, however how it analyses and uses that data in its serverless infrastructure gives you the performance to analyze Data Warehouse type data.
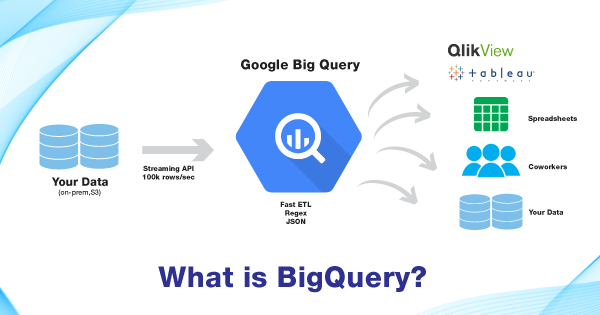
BigQuery allows you to create ETL processes to quickly transform data before presenting to the end user whatever that end user is.
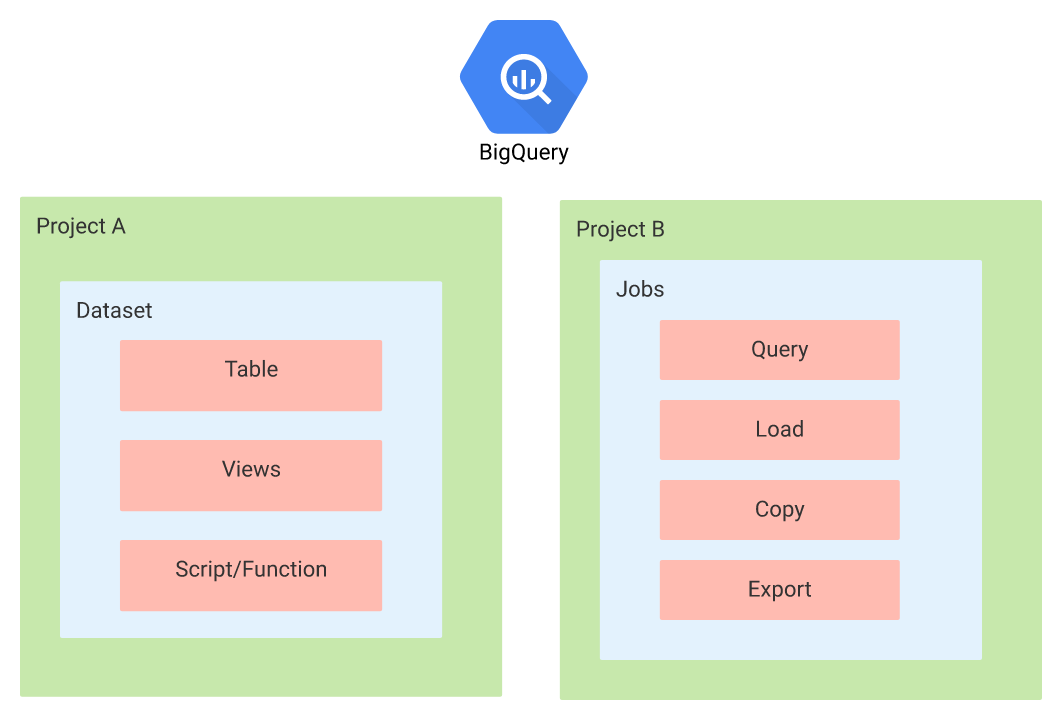
BigQuery has a hierarchical structure. Much like any RDBMS, the main hierarchy is:
- Organization – The top level of your setup
- Projects – You can have multiple projects, whereby you can split your use cases, these can be loosely thought of as servers if you’re - comparing to SQL Server
- Datasets – Datasets allow you to group and manage sets of tables beneath, when thinking of datasets you can compare them to RDBMS you - can compare them to databases
- Tables – Tables are assigned to datasets and work like normal tables you’d find in an RDBMS system
- View – Views work on top of tables, allowing you to create tailored views for your data.
- Script/Functions – These allow you to group scripts into handy files/repeatable functions to reduce code usage.
BigQuery also allows the use of things called jobs. Jobs are actions that BiqQuery runs for you. It allows you carry out all the main ETL actions you would usually need to take.
For its ETL type jobs it allows you the usual functionality needed to create these processes including:
- Querying
- Loading
- Copying
- Exporting