Introduction
Paging is the technique taking a large query result set and returning smaller chunks of that result set.
This is very important to be doing in SQL Server. The reason for this is that for any query we issue against SQL Server, it takes out different level grains of locks. To give a really simplified explanation the different levels are:
- Key Level
- Row Level
- Page Level
- Table Level
- Database Level
SQL Server also has rules as to when lower level locks are escalated to higher level ones. This is called Lock Escalation.
So think if you do a update TOP 1 SQL will take out a row lock on that specific row, locking that row from anybody else accessing it until you finish your updating. Now if you do an update top 100 SQL will take out 100 row locks, locking 100 rows from being accessed by anybody else until you have finished your reading.
You can already see that the more rows you bring back the more impact you’re having on other users.
Lock escalation happens when certain criteria are met internally within SQL. Its not documented by Microsoft as to the specifics, but over time SQL enthusiasts have gauged assumptions. 1 assumption is to the number of rows you would have to update to hit lock escalation. The magic number in the SQL Community is 4000.
So using this magic number you should always have in mind that you should not update/delete more than 4000 rows at a time, when you have to then you should implement paging to do it in chunks of 4000 at a time.
There are a few different ways to page through data in SQL, some are better than others. We will walk through them here.
Setup
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
IF NOT EXISTS (SELECT 1 FROM SYS.DATABASES WHERE NAME = 'PagingTechniques')
BEGIN
CREATE DATABASE PagingTechniques
END
GO
USE [PagingTechniques]
GO
CREATE TABLE [dbo].[PagingTechniquesTable] (UserID INT
,SubUserID INT
,DateCreated DATETIME,
CONSTRAINT [PK_PagingTechniquesTable] PRIMARY KEY CLUSTERED(UserID,SubUserID))
GO
DECLARE @UserAccountCount INT = 50
DECLARE @SubUserIDCount INT = 10000
DECLARE @UserID INT = 1
DECLARE @SubUserID INT = 1
WHILE @UserID < @UserAccountCount
BEGIN
WHILE @SubUserID <= @SubUserIDCount
BEGIN
INSERT INTO [dbo].[PagingTechniquesTable] (UserID,SubUserID,DateCreated)
VALUES (@UserID,@SubUserID,GETDATE())
SET @SubUserID+= 1
END
SET @SubUserID = 1
SET @UserID +=1
END
Offset Fetch Technique
This technique is by far the most popular amongst developers. Introduced in SQL Server 2012, the syntax of this allows for simplified code to execute a batched process. It does have a fairly major flaw however. Run the below code to create your test environment
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
DECLARE @Offset INT = 0
DECLARE @Fetch INT = 1000
DECLARE @RowCount INT = 1000
WHILE @RowCount = @Fetch
BEGIN
SELECT UserID,
SubUserID
FROM [dbo].[PagingTechniquesTable]
ORDER BY UserID,SubUserID
OFFSET @OFFSET ROWS
FETCH NEXT @FETCH ROWS ONLY
SET @RowCount = @@ROWCOUNT
SET @Offset += @Fetch
END
This script will iterate through your entire dataset bringing back 1000 rows in turn until it has pulled back every record in the table. The primary key is on UserAccountID and ContactID, you are only bringing back these columns and you are ordering by these columns so should be all good. However if you look at your execution plans it tells a different story. Go to the plan for your first execution. look at the number of rows read on the first iteration

1000 rows, performant query only read the rows it needed. Now go and check the 5th iteration

It has looked through 5000 rows, so it has looked through the first 5000 rows in the index and only brought back 1000 it needed. Not great but still performant. Now go look at the last iteration (or most likely the last iteration before you stopped the query)

I stopped the query after the 132nd iteration. As you can see it has read 132000 rows to bring back 1000. As you can probably tell, when it comes to offset fetch when working with a dataset, you will end up reading the entire dataset, which as you imagine with one as large as 10 million for example, would be horribly expensive.
Left Join Technique
The left join technique is used with data modifications. So updates and deletes. The main high level aim is to delete in batches and the left join to reduce your dataset for you, to remove the need for complex looping scripts. Your data from your first test should be unaffected, so you can use the same setup data. Run the below query against the same database with execution plan on.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
CREATE TABLE [dbo].[PagingTechniquesTable_Backup] (UserID INT
,SubUserID INT
,DateCreated DATETIME)
GO
DECLARE @BatchSize INT = 1000
DECLARE @RowCount INT = 1000
WHILE @RowCount = @BatchSize
BEGIN
DELETE TOP (@BatchSize) A
OUTPUT DELETED.UserID,DELETED.SubUserID,DELETED.DateCreated INTO [dbo].[PagingTechniquesTable_Backup]
FROM [dbo].PagingTechniquesTable A
LEFT JOIN [PagingTechniquesTable_Backup] B
ON A.UserID = B.UserID
AND A.SubUserID = B.SubUserID
WHERE B.UserID IS NULL
SET @RowCount = @@ROWCOUNT
END
In This technique, we create our backup table then on each iteration we output the deleted columns into this backup table. This means that on the next delete the left join will double check the backup table to ensure we dont look for the same records again.
Now looking at the execution plan again on the first iteration we will see the below:
In This technique, we create our backup table then on each iteration we output the deleted columns into this backup table. This means that on the next delete the left join will double check the backup table to ensure we dont look for the same records again.
Now looking at the execution plan again on the first iteration we will see the below:
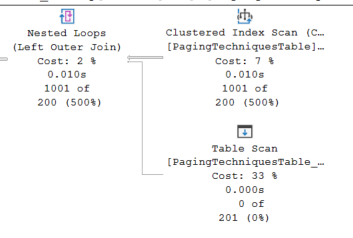
SQL is searching in the PagingTable then performing a nested loop join to the backup table. It picks up: 1001 rows from PagingTechniques 0 From PagingTechniquesTable_Backup
All good. Next look at the next iteration. We now get the below:
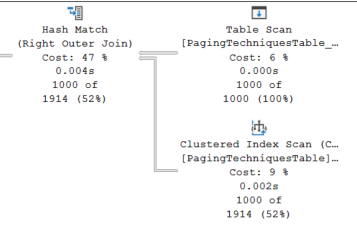
We are now pulling rows from PagingTechniquesTable_Backup then hash matching to paging techniques. It picks up: 1000 From PagingTechniquesTable_Backup 1000 rows from PagingTechniques
It is now reading 2000 rows because it needs to join the entire dataset from your backup table.
Now if you look at the last execution i stopped my script after 33 executions. We have the same join as before
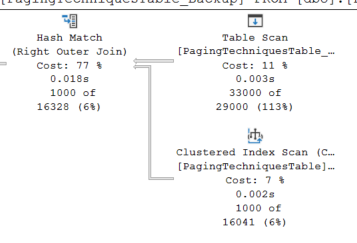
Its reading 33000 rows from PagingTechniquesTable_Backup 1000 Rows from PagingTechniques
Takeaway is the more rows you need to delete the more rows you are going to have to read. Again similar to the offset/fetch technique with larger datasets this will not be a great idea.
RowNumber Technique
This technique will be the most performant for large datasets with a little increased overhead initially. The purpose of this technique is to:
- Hold your dataset in a temp table
- Add a rownumber to the table usually an identity field
- Iterate through the table for a data modification increasing the row count each time
To start drop your database and run the setup again. Then continue with the below scripts
1
2
3
4
5
6
7
8
9
10
--Populate new table
SELECT UserID,
SubUserID,
'UserID:' + CONVERT(VARCHAR,UserID) + ', SubUserID:' + CONVERT(VARCHAR,SubUserID) AS [Description]
INTO dbo.PagingTechniquesDescription
FROM dbo.PagingTechniquesTable
--Create new column to backfill
ALTER TABLE PagingTechniquesTable
ADD [Description] VARCHAR(100)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
CREATE TABLE #RowsToUpdate (RowNumber INT IDENTITY(1,1),UserID INT, SubUserID INT, [Description] VARCHAR(100),
CONSTRAINT [PK_RowsToUpdate] PRIMARY KEY CLUSTERED (RowNumber,UserID,SubUserID))
INSERT INTO #RowsToUpdate (UserID,SubUserID,[Description])
SELECT a.UserID,
a.SubUserID,
b.[Description]
FROM dbo.PagingTechniquesTable A WITH(NOLOCK)
INNER JOIN dbo.PagingTechniquesDescription B WITH(NOLOCK)
ON A.UserID = B.UserID
AND A.SubUserID = B.SubUserID
DECLARE @BatchSize INT = 1000
DECLARE @RowCount INT = 1000
DECLARE @RowNumber INT = 0
WHILE @RowCount = @BatchSize
BEGIN
UPDATE TOP (1000) a
SET A.[DESCRIPTION] = B.[DESCRIPTION]
FROM dbo.PagingTechniquesTable A
INNER JOIN #RowsToUpdate b
ON A.UserID = B.UserID
AND A.SubUserID = B.SubUserID
WHERE B.RowNumber > @RowNumber
AND B.RowNumber <= @RowNumber + @BatchSize
SET @RowCount = @@ROWCOUNT
SET @RowNumber += @BatchSize
END
Digging into the execution plan we can see the performance. Look at the first iteration
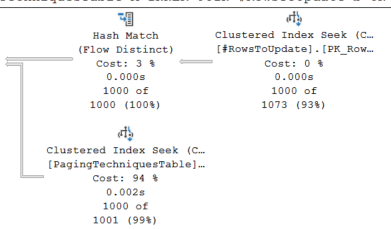
We have a clustered Index Seek on both the temp table and paging table. When we look at the number of rows read we see 1000 for both.
Now look at the last iteration 
We still have the same data access pattern. If we look at the number of rows read, we see 1000 for both again.
This is much more performant than the other 2 techniques, each iteration we are reading the same number of rows each time, this is because using the rownumber allows us to seek to the data we need, rather than carrying out wasteful reads.
This isn’t to say that for your loops you will get the same reads compared to your batch size. Dependent on the table layout and size of fields you may get more reads. However the takeaway is that with this technique it allows for seeking and will give you a similar number of reads each time, which considerably improves performance.